WECGridDB
Overview
The WECGridDB provides the central data management system for WEC-Grid simulation results and metadata. This SQLite-based database stores power system analysis results, WEC simulation data, and integration parameters across multiple software backends with standardized schemas for cross-platform validation.
Responsibilities
-
Data Persistence
- Store simulation results from PSS®E and PyPSA power system analysis
- Archive WEC-Sim hydrodynamic simulation outputs and metadata
- Maintain links between grid simulations and WEC farm integrations
-
Cross-Platform Integration
- Provide identical table schemas for PSS®E and PyPSA result comparison
- Enable validation studies across different power system software
- Support direct GridState DataFrame mapping for efficient data transfer
-
Time-Series Management
- Handle high-resolution WEC power data from detailed simulations
- Store grid component time-series at user-configurable intervals
- Maintain synchronized timestamps across all simulation data
Key Features
-
Multi-Backend Support
- Separate table sets for PSS®E and PyPSA with identical schemas
- Software-agnostic GridState data structure alignment
- Cross-platform result validation and comparison capabilities
-
WEC Integration Schema
- High-resolution WEC power time-series storage (Watts resolution)
- WEC simulation metadata including wave conditions and device parameters
- Farm-to-grid connection mapping with bus location tracking
-
Performance Optimization
- Composite primary keys for efficient time-series queries
- Strategic indexing on timestamp and simulation ID columns
- Transaction-safe operations with automatic rollback on errors
Database Schema
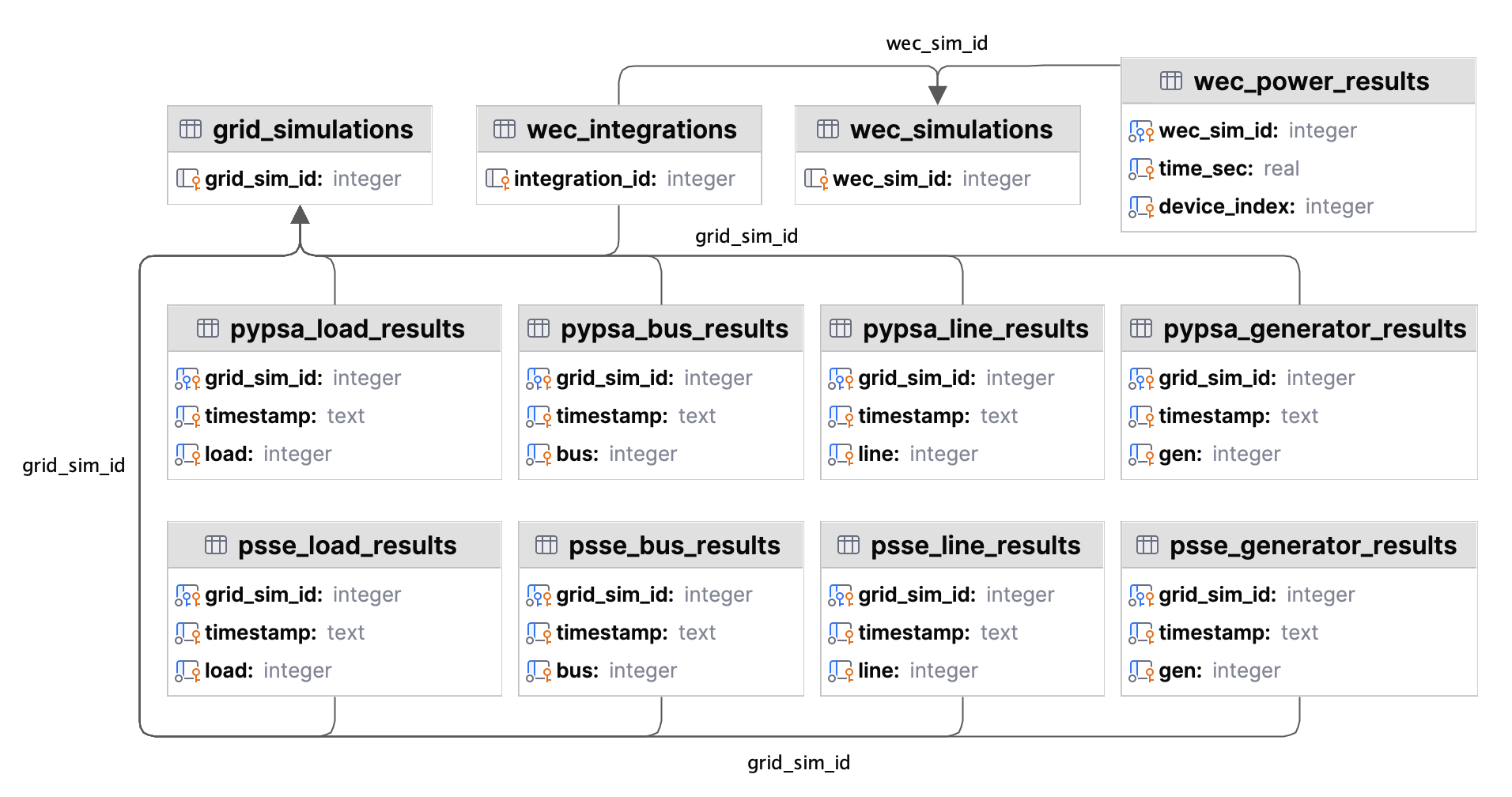
Metadata Tables
grid_simulations — Grid Simulation Metadata
| Column | Description | Type | Units |
|---|---|---|---|
| grid_sim_id | Primary key (auto-increment) | INTEGER | — |
| sim_name | Simulation name (optional) | TEXT | — |
| case_name | Power system case name | TEXT | — |
| psse | PSS®E backend flag | BOOLEAN | — |
| pypsa | PyPSA backend flag | BOOLEAN | — |
| sbase_mva | System base power | REAL | MVA |
| sim_start_time | Simulation start timestamp | TEXT | ISO-8601 |
| sim_end_time | Simulation end timestamp | TEXT | ISO-8601 |
| delta_time | Time-step size | INTEGER | s |
| notes | Simulation notes | TEXT | — |
| created_at | Record creation timestamp | TEXT | ISO-8601 |
Keys/Constraints: PRIMARY KEY(grid_sim_id)
Indexes: idx_grid_sim_time(sim_start_time), idx_grid_sim_case(case_name)
wec_simulations — WEC Simulation Parameters
| Column | Description | Type | Units |
|---|---|---|---|
| wec_sim_id | Primary key (auto-increment) | INTEGER | — |
| model_type | WEC device model (RM3, LUPA, etc.) | TEXT | — |
| sim_duration_sec | Total simulation duration | REAL | s |
| delta_time | Time-step size | REAL | s |
| wave_height_m | Significant wave height | REAL | m |
| wave_period_sec | Peak wave period | REAL | s |
| wave_spectrum | Spectrum type (PM, JONSWAP, etc.) | TEXT | — |
| wave_class | Wave class (irregular/regular) | TEXT | — |
| wave_seed | Random seed for wave generation | INTEGER | — |
| simulation_hash | Unique parameter combination hash | TEXT | — |
| created_at | Record creation timestamp | TEXT | ISO-8601 |
Keys/Constraints: PRIMARY KEY(wec_sim_id)
wec_integrations — Grid-WEC Simulation Links
| Column | Description | Type | Units |
|---|---|---|---|
| integration_id | Primary key (auto-increment) | INTEGER | — |
| grid_sim_id | FK to grid_simulations |
INTEGER | — |
| wec_sim_id | FK to wec_simulations |
INTEGER | — |
| farm_name | WEC farm identifier | TEXT | — |
| bus_location | Grid connection bus number | INTEGER | bus # |
| num_devices | Number of WEC devices in farm | INTEGER | — |
| created_at | Record creation timestamp | TEXT | ISO-8601 |
Keys/Constraints: PRIMARY KEY(integration_id), FOREIGN KEY(grid_sim_id), FOREIGN KEY(wec_sim_id)
Index: idx_wec_integration(grid_sim_id, wec_sim_id)
PSS®E Results Tables
psse_bus_results — Bus Voltage and Power Data
| Column | Description | Type | Units |
|---|---|---|---|
| grid_sim_id | FK to grid simulation | INTEGER | — |
| timestamp | Sample time | TEXT | ISO-8601 |
| bus | Bus number | INTEGER | — |
| bus_name | Bus label | TEXT | — |
| type | Bus type (Slack/PV/PQ) | TEXT | — |
| p | Net active power injection | REAL | pu on S_base |
| q | Net reactive power injection | REAL | pu on S_base |
| v_mag | Voltage magnitude | REAL | pu on V_base |
| angle_deg | Voltage angle | REAL | degrees |
| vbase | Nominal line-to-line voltage | REAL | kV |
Key: PRIMARY KEY(grid_sim_id, timestamp, bus)
Index: idx_psse_bus_time(grid_sim_id, timestamp)
psse_generator_results — Generator Output Data
| Column | Description | Type | Units |
|---|---|---|---|
| grid_sim_id | FK to grid simulation | INTEGER | — |
| timestamp | Sample time | TEXT | ISO-8601 |
| gen | Generator ID | INTEGER | — |
| gen_name | Generator label | TEXT | — |
| bus | Connected bus | INTEGER | — |
| p | Active power output | REAL | pu on S_base |
| q | Reactive power output | REAL | pu on S_base |
| mbase | Machine base power | REAL | MVA |
| status | Online flag (1/0) | INTEGER | — |
Key: PRIMARY KEY(grid_sim_id, timestamp, gen)
Index: idx_psse_gen_time(grid_sim_id, timestamp)
psse_load_results — Load Consumption Data
| Column | Description | Type | Units |
|---|---|---|---|
| grid_sim_id | FK to grid simulation | INTEGER | — |
| timestamp | Sample time | TEXT | ISO-8601 |
| load | Load ID | INTEGER | — |
| load_name | Load label | TEXT | — |
| bus | Connected bus | INTEGER | — |
| p | Active power demand | REAL | pu on S_base |
| q | Reactive power demand | REAL | pu on S_base |
| status | Connected flag (1/0) | INTEGER | — |
Key: PRIMARY KEY(grid_sim_id, timestamp, load)
Index: idx_psse_load_time(grid_sim_id, timestamp)
psse_line_results — Transmission Line Data
| Column | Description | Type | Units |
|---|---|---|---|
| grid_sim_id | FK to grid simulation | INTEGER | — |
| timestamp | Sample time | TEXT | ISO-8601 |
| line | Line ID | INTEGER | — |
| line_name | Line label | TEXT | — |
| ibus | From bus | INTEGER | — |
| jbus | To bus | INTEGER | — |
| line_pct | Percent of thermal rating | REAL | % |
| status | In-service flag (1/0) | INTEGER | — |
Key: PRIMARY KEY(grid_sim_id, timestamp, line)
Index: idx_psse_line_time(grid_sim_id, timestamp)
PyPSA Results Tables
Cross-Platform Schema Consistency
PyPSA result tables use identical schemas to PSS®E tables for direct comparison:
pypsa_bus_results— Schema identical topsse_bus_resultspypsa_generator_results— Schema identical topsse_generator_resultspypsa_load_results— Schema identical topsse_load_resultspypsa_line_results— Schema identical topsse_line_results
Keys/Indexes: Same composite primary keys and timestamp indexes as PSS®E tables
WEC Time-Series Data
wec_power_results — High-Resolution WEC Device Output
| Column | Description | Type | Units |
|---|---|---|---|
| wec_sim_id | FK to wec_simulations |
INTEGER | — |
| time_sec | Simulation time | REAL | s |
| device_index | Device index within farm | INTEGER | — |
| p_w | Active power output | REAL | W |
| q_var | Reactive power output | REAL | VAR |
| wave_elevation_m | Wave surface elevation | REAL | m |
Key: PRIMARY KEY(wec_sim_id, time_sec, device_index)
Index: idx_wec_power_time(wec_sim_id, time_sec)
API Integration
Database Initialization and Configuration
from wecgrid import Engine
# Initialize engine with database configuration
engine = Engine()
# First-time setup: configure database path (persists to user config)
engine.database.set_database_path(r"C:\path\to\WECGrid.db")
# Or initialize new database with schema
engine.database.initialize_database(r"C:\path\to\new_database.db")
Alternatively, set an environment variable to point to the database (no code needed):
# Windows PowerShell
$env:WECGRID_DB_PATH = "C:\path\to\WECGrid.db"
# macOS/Linux
export WECGRID_DB_PATH=~/path/to/WECGrid.db
Note: WEC‑Grid stores persistent configuration in a user‑writable directory (e.g., ~/.wecgrid/).
Storing Simulation Results
# Run grid simulation (PyPSA shown; add PSS®E similarly if available)
engine.case("IEEE_14_bus.raw")
engine.load(["pypsa"]) # or ["psse"], or both
engine.apply_wec(farm_name="Test Farm", wec_sim_id=101, bus_location=14)
engine.simulate()
# Save results to database
sim_id = engine.database.save_sim(
sim_name="WEC Integration Study",
notes="Testing 10-device RM3 farm at bus 14"
)
Querying Simulation Data
# Get all grid simulations
simulations = engine.database.grid_sims()
# Get WEC simulation metadata
wec_runs = engine.database.wecsim_runs()
# Load specific simulation results
grid_state = engine.database.pull_sim(grid_sim_id=123, software="psse")
# Custom SQL queries
bus_voltages = engine.database.query(
"SELECT * FROM psse_bus_results WHERE grid_sim_id = ? AND bus = ?",
params=(sim_id, 14),
return_type="df"
)
Cross-Platform Validation
# Compare PSS®E and PyPSA results for same scenario
psse_buses = engine.database.query(
"SELECT timestamp, bus, v_mag, p, q FROM psse_bus_results WHERE grid_sim_id = ?",
params=(sim_id,), return_type="df"
)
pypsa_buses = engine.database.query(
"SELECT timestamp, bus, v_mag, p, q FROM pypsa_bus_results WHERE grid_sim_id = ?",
params=(sim_id,), return_type="df"
)
# Direct comparison enabled by identical schemas
voltage_diff = abs(psse_buses['v_mag'] - pypsa_buses['v_mag'])
System Requirements
Database Engine
- SQLite 3.x: Embedded database engine (no server required)
- Python sqlite3: Standard library module for database operations
- pandas: DataFrame integration for efficient data handling
Storage Considerations
- Database Size: Scales with simulation duration and component count
- Time-Series Storage: High-resolution WEC data requires significant space
- Indexing: Composite indexes optimize time-series query performance
Configuration Management
- Environment Variable:
WECGRID_DB_PATHcan set the database path - User Config:
database_config.jsonstored in your user config dir (e.g.,~/.wecgrid/) - First-Time Setup: User-guided configuration via
set_database_path()orinitialize_database()
Performance Considerations
Query Optimization
- Composite Primary Keys: Efficient time-series access patterns
- Strategic Indexing: Timestamp and simulation ID indexes for fast lookups
- Table Partitioning: Separate PSS®E/PyPSA tables prevent cross-contamination
Data Management
- Transaction Safety: Automatic rollback on operation failures
- Batch Operations: Efficient bulk inserts for time-series data
- Memory Usage: DataFrame-based operations minimize memory overhead
Scaling Characteristics
- Simulation Count: Linear scaling with number of archived simulations
- Time Resolution: Storage requirements scale with time-series frequency
- Component Size: Database size proportional to power system complexity
Common Issues
Database Configuration
Symptom: Database path not configured error on startup
Schema Migration
Symptom: Missing columns in existing database tables
Cross-Platform Data Validation
Symptom: Different results between PSS®E and PyPSA backends
# Verify identical system base power
psse_info = engine.database.query(
"SELECT sbase_mva FROM grid_simulations WHERE grid_sim_id = ? AND psse = 1",
params=(sim_id,)
)
Large Time-Series Performance
Symptom: Slow queries on WEC power results table
# Use time-based filtering for better performance
recent_power = engine.database.query(
"SELECT * FROM wec_power_results WHERE wec_sim_id = ? AND time_sec > ?",
params=(wec_sim_id, start_time), return_type="df"
)
See Also
- PowerSystemModeler: GridState data structures and schemas
- PSS®E Integration: Commercial power system backend
- PyPSA Integration: Open-source power system backend
- WEC Integration: WEC farm and device data management